
A Kubernetes Service Mesh Comparison
As microservices architecture continues to evolve, interservice communication has become a significant challenge to manage. Service meshes are becoming the standard solution, but how do popular and up-and-coming service meshes compare?
Written by Guillaume Dury
This article was originally published in toptal.com Blog. Follow total.com for more articles.

When discussing microservices architecture and containerization, one set of production-proven tools has captured most of the attention in recent years: the service mesh.
Indeed, microservices architecture and Kubernetes (often stylized “K8s”) have quickly become the norm for scalable apps, making the problem of managing communications between services a hot topic—and service meshes an attractive solution. I myself have used service meshes in production, specifically Linkerd, Istio, and an earlier form of Ambassador. But what do service meshes do, exactly? Which one is the best to use? How do you know whether you should use one at all?
To answer these questions, it helps to understand why service meshes were developed. Historically, traditional IT infrastructure had applications running as monoliths. One service ran on one server; if it needed more capacity, the solution was to scale it vertically by provisioning a bigger machine.
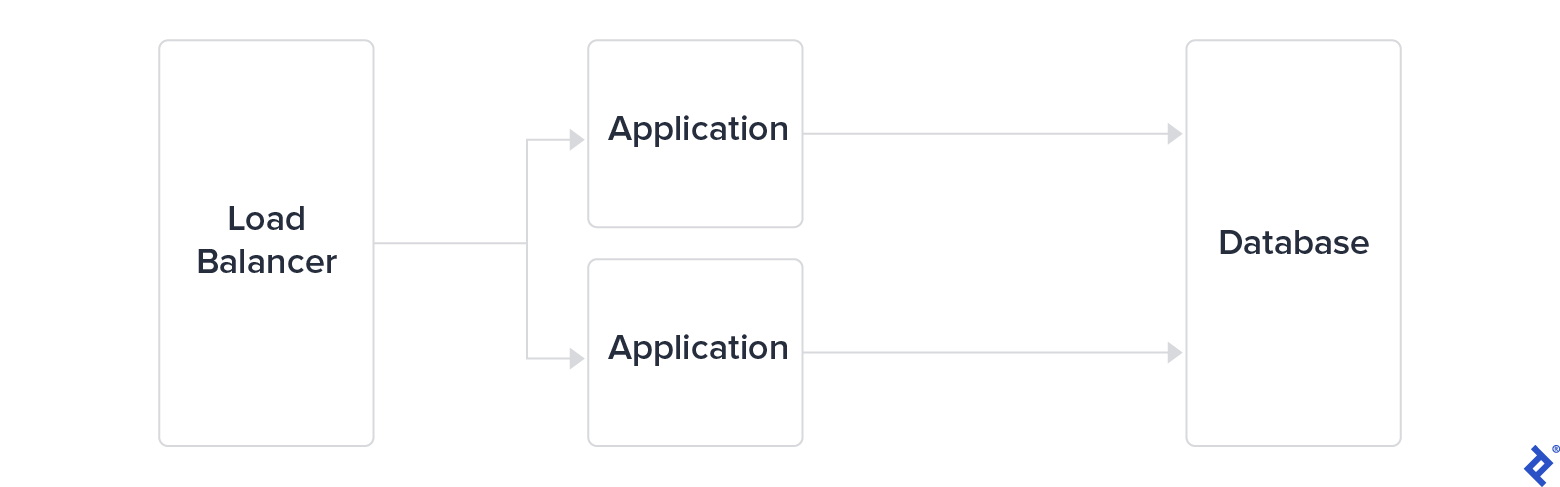
Reaching the limits of this approach, big tech companies rapidly adopted a three-tier architecture, separating a load balancer from application servers and a database tier. While this architecture remained somewhat scalable, they decided to break down the application tier into microservices. The communication between these services became critical to monitor and secure in order for applications to scale.
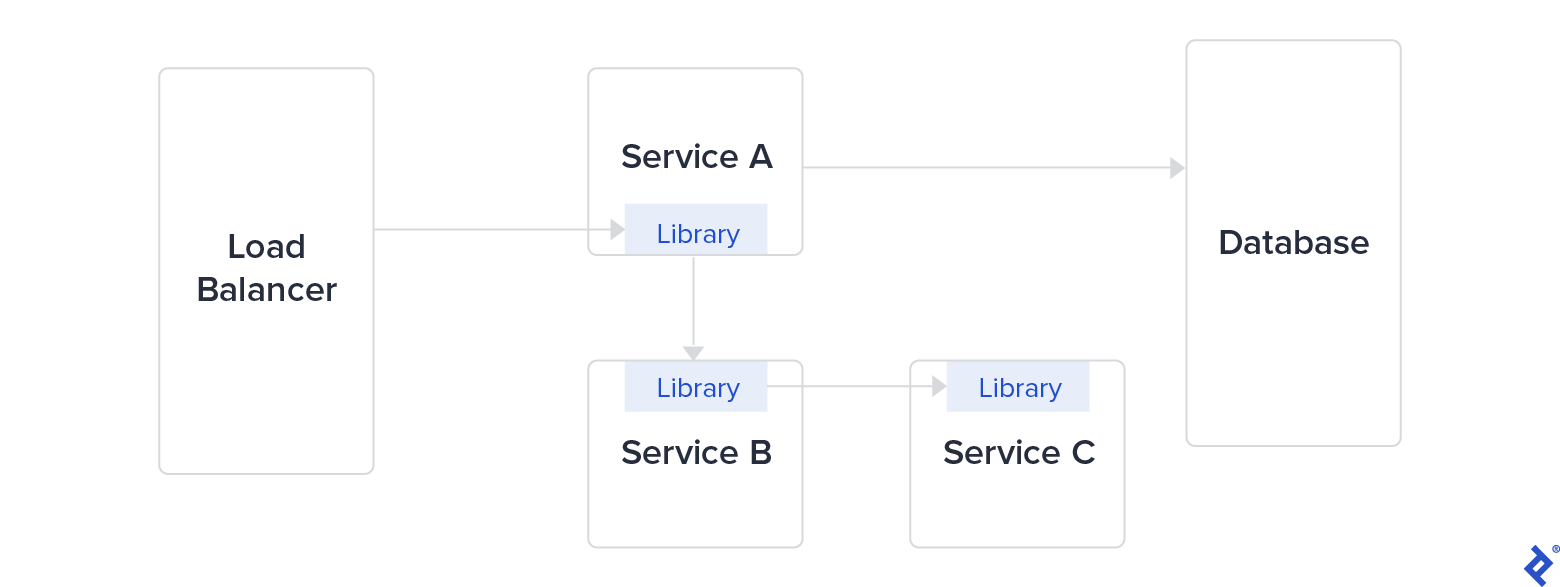
To allow interservice communication, these companies developed in-house libraries: Finagle at Twitter, Hystrix at Netflix, and Stubby at Google (which became gRPC in 2016). These libraries aimed to fix problems raised by microservices architecture: security between services, latency, monitoring, and load balancing. But managing a big library as a dependency—in multiple languages—is complex and time-consuming.

In the end, that type of library was replaced with an easier-to-use, lightweight proxy. Such proxies were externally independent of the application layer—potentially transparent for the application—and easier to update, maintain, and deploy. Thus, the service mesh was born.
What Is a Service Mesh?
A service mesh is a software infrastructure layer for controlling communication between services; it’s generally made of two components:
- The data plane, which handles communications near the application. Typically this is deployed with the application as a set of network proxies, as illustrated earlier.
- The control plane, which is the “brain” of the service mesh. The control plane interacts with proxies to push configurations, ensure service discovery, and centralize observability.
Service meshes have three main goals around interservice communication:
- Connectivity
- Security
- Observability
Connectivity
This aspect of service mesh architecture allows for service discovery and dynamic routing. It also covers communication resiliency, such as retries, timeouts, circuit breaking, and rate limiting.
A staple feature of service meshes is load balancing. All services being meshed by proxies allows for the implementation of load-balancing policies between services, such as round robin, random, and least requests. Those policies are the strategy used by the service mesh to decide which replica will receive the original request, just like if you had tiny load balancers in front of each service.
Finally, service meshes offer routing control in the form of traffic shifting and mirroring.
Security
In traditional microservices architecture, services communicate between themselves with unencrypted traffic. Unencrypted internal traffic is nowadays considered a bad practice in terms of security, particularly for public cloud infrastructure and zero-trust networks.
On top of protecting the privacy of client data where there’s no direct control over hardware, encrypting internal traffic adds a welcome layer of extra complexity in case of a system breach. Hence, all service meshes use mutual TLS (mTLS) encryption for interservice communication, i.e., all interproxy communication.
Service meshes can even enforce complex matrices of authorization policy, allowing or rejecting traffic based on policies targeting particular environments and services.
Observability
The goal of service meshes is to bring visibility to interservice communications. By controlling the network, a service mesh enforces observability, providing layer-seven metrics, which in turn allow for automatic alerts when traffic reaches some customizable threshold.
Usually supported by third-party tools or plug-ins like Jaeger or Zipkin, such control also allows for tracing by injecting HTTP tracing headers.
Service Mesh Benefits
The service mesh was created to offset some of the operational burden created by a microservices architecture. Those with experience in microservices architectures know that they take a significant amount of work to operate on a daily basis. Taking full advantage of the potential of microservices normally requires external tooling to handle centralized logging, configuration management, and scalability mechanisms, among others. Using a service mesh standardizes these capabilities, and their setup and integration.
Service mesh observability, in particular, provides extremely versatile debugging and optimization methods. Thanks to granular and complete visibility on exchanges between services, engineers—particularly SREs—can more quickly troubleshoot possible bugs and system misconfigurations. With service mesh tracing, they can follow a request from its entry into the system (at a load balancer or external proxy) all the way to private services inside the stack. They can use logging to map a request and record the latency it encounters in each service. The end result: detailed insights into system performance.
Traffic management provides powerful possibilities before ramping up to a full release of a new versions of a service:
- Reroute small percentages of requests.
- Even better, mirror production requests to a new version to test its behavior with real-time traffic.
- A/B test any service or combination of services.
Service meshes streamline all of the above scenarios, making it easier to avoid and/or mitigate any surprises in production.
Kubernetes Service Mesh Comparison
In many ways, service meshes are the ultimate set of tools for microservices architecture; many of them run on one of the top container orchestration tools, Kubernetes. We selected three of the main service meshes running on Kubernetes today: Linkerd (v2), Istio, and Consul Connect. We’ll also discuss some other service meshes: Kuma, Traefik Mesh, and AWS App Mesh. While currently less prominent in terms of usage and community, they’re promising enough to review here and to keep tabs on generally.
A Quick Note About Sidecar Proxies
Not all Kubernetes service meshes take the same architectural approach, but a common one is to leverage the sidecar pattern. This involves attaching a proxy (sidecar) to the main application to intercept and regulate the inbound and outbound network traffic of the application. In practice, this is done in Kubernetes via a secondary container in each application pod that will follow the life cycle of the application container.
There are two main advantages to the sidecar approach to service meshes:
- Sidecar proxies are independent from the runtime and even the programming language of the application.
- This means it’s easy to enable all the features of a service mesh wherever it’s to be used, throughout the stack.
- A sidecar has the same level of permissions and access to resources as the application.
- The sidecar can help monitor resources used by the main application, without the need to integrate monitoring into the main application codebase.
But sidecars are a mixed blessing because of how they directly impact an application:
- Sidecar initialization may deadlock the starting mechanism of an application.
- Sidecar proxies add potential latency on top of your application.
- Sidecar proxies also add a resource footprint that can cost a significant amount of money at scale.
Given those advantages and drawbacks, the sidecar approach is frequently a subject of debate in the service mesh community. That said, four of the six service meshes compared here use the Envoy sidecar proxy, and Linkerd uses its own sidecar implementation; Traefik Mesh does not use sidecars in its design.
Linkerd Review
Linkerd, which debuted in 2017, is the oldest service mesh on the market. Created by Buoyant (a company started by two ex-Twitter engineers), Linkerd v1 was based on Finagle and Netty.
Linkerd v1 was described as being ahead of its time since it was a complete, production-ready service mesh. At the same time, it was a bit heavy in terms of resource use. Also, significant gaps in documentation made it difficult to set up and run in production.
With that, Buoyant had a chance to work with a complete production model, gain experience from it, and apply that wisdom. The result was Conduit, the complete Linkerd rewrite the company released in 2018 and renamed Linkerd v2 later that year. Linkerd v2 brought with it several compelling improvements; since Buoyant’s active development of Linkerd v1 ceased long ago, our mentions of “Linkerd” throughout the rest of this article refer to v2.
Fully open source, Linkerd relies on a homemade proxy written in Rust for the data plane and on source code written in Go for the control plane.
Connectivity
Linkerd proxies have retry and timeout features but have no circuit breaking or delay injection as of this writing. Ingress support is extensive; Linkerd boasts integration with the following ingress controllers:
- Traefik
- Nginx
- GCE
- Ambassador
- Gloo
- Contour
- Kong
Service profiles in Linkerd offer enhanced routing capabilities, giving the user metrics, retry tuning, and timeout settings, all on a per-route basis. As for load balancing, Linkerd offers automatic proxy injection, its own dashboard, and native support for Grafana.
Security
The mTLS support in Linkerd is convenient in that its initial setup is automatic, as is its automatic daily key rotation.
Observability
Out of the box, Linkerd stats and routes are observable via a CLI. On the GUI side, options include premade Grafana dashboards and a native Linkerd dashboard.
Linkerd can plug into an instance of Prometheus.
Tracing can be enabled via an add-on with OpenTelemetry (formerly OpenCensus) as the collector, and Jaeger doing the tracing itself.
Installation
Linkerd installation is done by injecting a sidecar proxy, which is done by adding an annotation to your resources in Kubernetes. There are two ways to go about this:
- Using a Helm chart. (For many, Helm is the go-to configuration and template manager for Kubernetes resources.)
- Installing the Linkerd CLI, then using that to install Linkerd into a cluster.
The second method starts with downloading and running an installation script:
curl -sL https://run.linkerd.io/install | sh
From there, the Linkerd CLI tool linkerd provides a useful toolkit that helps install the rest of Linkerd and interact with the app cluster and the control plane.
linkerd check --pre will run all the preliminary checks necessary for your Linkerd install, providing clear and precise logs on why a potential Linkerd install might not work just yet. Without --pre, this command can be used for post-installation debugging.
The next step is to install Linkerd in the cluster by running:
linkerd install | kubectl apply -f -
Linkerd will then install many different components with a very tiny resource footprint; hence, they themselves have a microservices approach:
- linkerd-controller, which provides the public API with which the CLI and dashboard interact
- linkerd-identity, which provides the certificate authority to implement mTLS
- linkerd-proxy-injector, which handles the injection of the proxy by mutating the configuration of a pod
- linkerd-web, which serves up a dashboard allowing the monitoring of deployments and pods, as well as internal Linkerd components
Linkerd bases most of its configuration on CustomResourceDefinitions (CRDs). This is considered the best practice when developing Kubernetes add-on software—it’s like durably installing a plug-in in a Kubernetes cluster.
Adding distributed tracing—which may or may not be what Linkerd users are actually after, due to some common myths—requires another step with linkerd-collector and linkerd-jaeger. For that, we would first create a config file:
cat >> config.yaml << EOF
tracing:
enabled: true
EOF
To enable tracing, we would run:
linkerd upgrade --config config.yaml | kubectl apply -f -
As with any service mesh based on sidecar proxies, you will need to modify your application code to enable tracing. The bulk of this is simply adding a client library to propagate tracing headers; it then needs to be included in each service.
The traffic split feature of Linkerd, exposed through its Service Mesh Interface (SMI)-compliant API, already allows for canary releases. But to automate them and traffic management, you will also need external tooling like Flagger.
Flagger is a progressive delivery tool that will assess what Linkerd calls the “golden” metrics: “request volume, success rate, and latency distributions.” (Originally, Google SREs used the term golden signals and included a fourth one—saturation—but Linkerd doesn’t cover it because that would require metrics that are not directly accessible, such as CPU and memory usage.) Flagger tracks these while splitting traffic using a feedback loop; hence, you can implement automated and metrics-aware canary releases.
After delving into the installation process, it becomes clear that to have a Linkerd service mesh operational and exploiting commonly desired capabilities, it’s easy to end up with at least a dozen services running. That said, more of them are supplied by Linkerd upon installation than with other service meshes.
Linkerd Service Mesh Summary
Advantages:
Linkerd benefits from the experience of its creators, two ex-Twitter engineers who had worked on the internal tool, Finagle, and later learned from Linkerd v1. As one of the first service meshes, Linkerd has a thriving community (its Slack has more than 5,000 users, plus it has an active mailing list and Discord server) and an extensive set of documentation and tutorials. Linkerd is mature with its release of version 2.9, as evidenced by its adoption by big corporations like Nordstrom, eBay, Strava, Expedia, and Subspace. Paid, enterprise-grade support from Buoyant is available for Linkerd.
Drawbacks:
There’s a pretty strong learning curve to use Linkerd service meshes to their full potential. Linkerd is only supported within Kubernetes containers (i.e., there’s no VM-based, “universal” mode). The Linkerd sidecar proxy is not Envoy. While this does allow Buoyant to tune it as they see fit, it removes the inherent extensibility that Envoy offers. It also means Linkerd is missing support for circuit breaking, delay injection, and rate limiting. No particular API is exposed to control the Linkerd control plane easily. (You can find the gRPC API binding, though.)
Linkerd has made great progress since v1 in its usability and ease of installation. The lack of an officially exposed API is a notable omission. But thanks to otherwise well-thought-out documentation, out-of-the-box functionality in Linkerd is easy to test.
Consul Connect Review
Our next service mesh contender, Consul Connect, is a unique hybrid. Consul from HashiCorp is better known for its key-value storage for distributed architectures, which has been around for many years. After the evolution of Consul into a complete suite of service tools, HashiCorp decided to build a service mesh on top of it: Consul Connect.
To be precise about its hybrid nature:
The Consul Connect data plane is based on Envoy, which is written in C++. The control plane of Consul Connect is written in Go. This is the part that is backed by Consul KV, a key-value store.
Like most of the other service meshes, Consul Connect works by injecting a sidecar proxy inside your application pod. In terms of architecture, Consul Connect is based around agents and servers. Out of the box, Consul Connect is meant to have high availability (HA) using three or five servers as a StatefulSet specifying pod anti-affinity. Pod anti-affinity is the practice of making sure pods of a distributed software system won’t end up on the same node (server), thereby guaranteeing availability in case any single node fails.
Connectivity
There’s not much that makes Consul Connect stand out in this area; it provides what any service mesh does (which is quite a bit), plus layer-seven features for path-based routing, traffic shifting, and load balancing.
Security
As with the other service meshes, Consul Connect provides basic mTLS capabilities. It also features native integration between Consul and Vault (also by HashiCorp), which can be used as a CA provider to manage and sign certificates in a cluster.
Observability
Consul Connect takes the most common observability approach by incorporating Envoy as a sidecar proxy to provide layer-seven capabilities. Configuring the UI of Consul Connect to fetch metrics involves changing a built-in configuration file and also enabling a metric provider like Prometheus. It’s also possible to configure some Grafana dashboards to show relevant service-specific metrics.
Installation
Consul Connect is installed into a Kubernetes cluster using a Helm chart:
helm repo add hashicorp https://helm.releases.hashicorp.com
You will need to modify the default values.yaml if you want to enable the UI or make the Consul Connect module inject its sidecar proxy:
helm install -f consul-values.yml hashicorp hashicorp/consul
To consult members and check the various nodes, Consul recommends execing into one of the containers then using the CLI tool consul.
To serve up the out-of-the-box web UI that Consul provides, run kubectl port-forward service/hashicorp-consul-ui 18500:80.
Consul Connect Service Mesh Summary
Advantages:
- Consul is backed by HashiCorp; as a freemium product, there is also an enterprise version with added features that offers enterprise-level support. In terms of development team experience, Consul is one of the oldest tools on the market.
- Consul has a solid enterprise community and has been known to run on infrastructure with 50,000 nodes. Also, it’s been around since 2014, making it a mature product relative to the market.
- Consul Connect runs well inside a VM, thanks to native support.
- With Consul Connect, it’s possible to achieve app integrations as deep as the pre-service-mesh implementations at top-tier tech companies. This is thanks to the exposure of a fully documented, library-level API.
Drawbacks:
- Consul Connect has a steeper learning curve than the other service meshes and will need more tuning to run visual dashboards and metrics.
- HashiCorp’s documentation is not straightforward, leaving users to dig and experiment to configure it correctly.
- Traffic management documentation is hard to find and mostly consists of links to Envoy’s documentation, which doesn’t provide details about Consul Connect traffic management in particular.
- The SMI interface of Consul Connect is still experimental.
Consul Connect can be a very good choice for those who seek an enterprise-grade product. HashiCorp is known for the quality of its products, and Consul Connect is no exception. I can see two strong advantages here compared to other service meshes: strong support from the company with the enterprise version and a tool ready for all kinds of architectures (not just Kubernetes).
Istio Review
In May 2017, Google, IBM, and Lyft announced Istio. When Istio entered the race of service mesh tools, it gained very good exposure in the tech space. Its authors have added features based on user feedback all the way through version 1.9.
Istio promised important new features over its competitors at the time: automatic load balancing, fault injection, and many more. This earned it copious attention from the community, but as we’ll detail below, using Istio is far from trivial: Istio has been recognized as particularly complex to put into production.
Historically, the Istio project has bounced around frequently in terms of source code changes. Once adopting a microservice architecture for the control plane, Istio has now (since version 1.5) moved back to a monolithic architecture. Istio’s rationale for returning to centralization was that microservices were hard for operators to monitor, the codebase was too redundant, and the project had reached organizational maturity—it no longer needed to have many small teams working in silos.
However, along the way Istio gained notoriety for having one of the highest volumes of open GitHub issues. As of this writing, the count stands at about 800 issues open and about 12,000 closed. While issue counts can be deceiving, in this case, they do represent a meaningful improvement in terms of previously broken features and out-of-control resource usage.
Connectivity
Istio is pretty strong at traffic management compared to Consul Connect and Linkerd. This is thanks to an extensive offering of sub-features: request routing, fault injection, traffic shifting, request timeouts, circuit breaking, and controlling ingress and egress traffic to the service mesh. The notion of virtual services and destination rules makes it very complete in terms of traffic management.
However, all those possibilities come with a learning curve, plus the management of those new resources on your Kubernetes cluster.
Security
Istio boasts a comprehensive set of security-related tools, with two main axes: authentication and authorization. Istio can enforce different levels of policies on different scopes: workload-specific, namespacewide, or meshwide. All such security resources are managed through Istio CRDs such as AuthorizationPolicy or PeerAuthentication.
Beyond the standard mTLS support, Istio can also be configured to accept or reject unencrypted traffic.
Observability
Here, Istio is pretty advanced out of the box, with several types of telemetry offering solid insights into the service mesh. Metrics are based on the four golden signals (latency, traffic, errors, and, to some extent, saturation).
Notably, Istio provides metrics for the control plane itself. It also serves distributed traces and access logs, boasting explicit compatibility with Jaeger, Lightstep, and Zipkin to enable tracing.
There is no native dashboard, but there is official support for the Kiali management console.
Installation
Installation is as straightforward as following the official steps. Istio is also natively integrated into GKE as a beta feature, but there GKE uses Istio 1.4.X, the older microservices version as opposed to the latest monolith version.
A native install starts with downloading the latest release:
curl -L https://istio.io/downloadIstio | sh -
After cding into the newly created istio-* folder, you can add it to your path so you can use the istioctl utility tool:
export PATH=$PWD/bin:$PATH
From there, you can install Istio to your Kubernetes cluster via istioctl:
istioctl install
This will install Istio with a default profile. istioctl profiles allow you to create different installation configurations and switch between them if necessary. But even in a single-profile scenario, you can deeply customize the install of Istio by modifying some CRDs.
Istio resources will be harder to manage as you will need to manage several kinds of CRDs—VirtualService, DestinationRule, and Gateway at a minimum—to make sure traffic management is in place.
- A
VirtualServiceresource is a configuration declaring a service and the different routing rules that are applied to requests. - A
DestinationRuleresource is used to group and enforce target-specific traffic policies. - A
Gatewayresource is created to manage inbound and outbound service mesh traffic (i.e., additional Envoy proxies, but running at the edge rather than as sidecars.)
The semantic details are beyond the scope of this review, but let’s look at a quick example showing each of these working together. Suppose we have an e-commerce website with a service called products. Our VirtualService might look like this:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: products-route
namespace: ecommerce
spec:
hosts:
- products # interpreted as products.ecommerce.svc.cluster.local
http:
- match:
- uri:
prefix: "/listv1"
- uri:
prefix: "/catalog"
rewrite:
uri: "/listproducts"
route:
- destination:
host: products # interpreted as products.ecommerce.svc.cluster.local
subset: v2
- route:
- destination:
host: products # interpreted asproducts.ecommerce.svc.cluster.local
subset: v1
The corresponding DestinationRule could then be:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: products
spec:
host: products
trafficPolicy:
loadBalancer:
simple: RANDOM # or LEAST_CONN or ROUND_ROBIN
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
- name: v3
labels:
version: v3
Lastly, our Gateway:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cert-manager-gateway
namespace: istio-system
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
With these three files in place, an Istio installation would be ready to handle basic traffic.
Istio Service Mesh Summary
Advantages:
- Among the different service meshes, Istio is the one with the biggest online community as of this writing. With more than 10 times the Stack Overflow results as either of its main competitors, it’s the most talked-about service mesh on the web; its GitHub contributors are likewise an order of magnitude beyond those of Linkerd.
- Istio supports both Kubernetes and VM modes; the latter is in beta as of version 1.9.
Drawbacks:
- Istio is not free, in two senses:
- Its requirements are high in terms of the time needed to read the documentation, set it up, make it work properly, and maintain it. Depending on infrastructure size and the number of services, Istio will take several weeks to several months of full-time work to be fully functional and integrated into production.
- It also adds a significant amount of resource overhead: It will take 350 millicores (mCPU) for the Envoy container per 1,000 requests per second (RPS). Even the control plane itself can be resource-consuming. (Previously, resource usage would be hard to predict, but after some effort,
istiodhas stabilized around using 1 vCPU and 1.5 GB of memory.)
- It has no native admin dashboard, unlike Linkerd.
- Istio requires the use of its own ingress gateway.
- The Istio control plane is only supported within Kubernetes containers (i.e., there’s no VM mode, unlike with the data plane of Istio).
Istio is a great example of tech giants coming together to create an open-source project to address a challenge they’re all facing. It took some time for the Istio project as a whole to structure itself (recalling the microservices-to-monolith architectural shift) and resolve its many initial issues. Today, Istio is doing absolutely everything one would expect from a service mesh and can be greatly extended. But all these possibilities come with steep requirements in terms of knowledge, work hours, and computing resources to support its usage in a production environment.
Kuma Quick Review
Created by Kong and then open-sourced, Kuma reached 1.0 in late 2020. To some extent, it was created in response to the first service meshes being rather heavy and difficult to operate.
Its feature list suggests it to be very modular; the idea behind Kuma is to orient it toward integration with applications already running on Kubernetes or other infrastructure.
- In the area of traffic management, Kuma offers common service mesh features like fault injection and circuit breaking.
- Beyond interservice mTLS encryption, exchanges between the data plane and the control plane are secured in Kuma via a data plane proxy token.
- Observability is defined in Kuma via different traffic policies around metrics, tracing, and logging.
- Service discovery is available through Kuma thanks to its own DNS resolver running on port 5653 of the control plane.
- Kuma has a strong emphasis on multimesh functionality: You can easily combine several Kubernetes clusters or VM environments into a common Kuma cluster with its multizone deployment type.
- Kuma easily integrates with Kong Gateway for existing Kong users.
The universal (non-Kubernetes) version of Kuma requires PostgreSQL as a dependency, and Kong’s CTO has been notably against supporting SMI. But Kuma was developed with the idea of multicloud and multicluster deployments from the start, and its dashboard reflects this.
While Kuma is still young in the service mesh space, with few cases of production use so far, it’s an interesting and promising contender.
Traefik Mesh Quick Review
Originally named Maesh, Traefik Mesh (by Traefik Labs) is another newcomer in the service mesh tooling race. The project mission is to democratize the service mesh by making it easy to use and configure; the developers’ experience with the well-thought-out Traefik Proxy put them in a prime position to accomplish that.
- Traffic management features in Traefik Mesh include circuit breaking and rate limiting.
- In terms of observability, Traefik Mesh features native OpenTracing Support and out-of-the-box metrics (the standard installation automatically includes Prometheus and Grafana), which saves setup time.
- For security—aside from mTLS—the specifications are SMI-compliant and Traefik Mesh allows the fine-tuning of traffic permissions through access control.
Traefik Mesh needs CoreDNS to be installed on the cluster. (While Azure has used CoreDNS by default since 1.12, GKE defaults to kube-dns as of this writing, meaning there’s a significant extra step involved in that case.) It also lacks multicluster capabilities.
That said, Traefik Mesh is unique within our service mesh comparison in that it doesn’t use sidecar injection. Instead, it’s deployed as a DaemonSet on all nodes to act as a proxy between services, making it non-invasive. Overall, Traefik Mesh is simple to install and use.
AWS App Mesh Quick Review
In the world of cloud providers, AWS is the first one to have implemented a native service mesh pluggable with Kubernetes (or EKS in particular) but also its other services. AWS App Mesh was released in November 2018 and AWS has been iterating on it since then. The main advantage of AWS App Mesh is the preexisting AWS ecosystem and market position; the big community behind AWS overall will continue to drive its usage and usability.
- Traffic management in AWS App Mesh includes circuit breaking on top of common features.
- Since AWS App Mesh is hosted by AWS, it’s a fully managed service, which means not having to worry about resource usage or control plane availability.
- Observability in AWS App Mesh can be done through Prometheus or AWS X-Ray.
The project is not open source, doesn’t support SMI, and there’s not much info online about HA standards for the control plane. AWS App Mesh is more complex to set up than other Kubernetes-native service meshes and has very little community online (24 answers on Stack Overflow, 400 stars on GitHub) but that’s because users are meant to benefit from AWS support.
AWS App Mesh has native integration with AWS, starting with EKS and extending to other AWS services like ECS (Fargate) and EC2. Unlike Traefik Mesh, it has multicluster support. Plus, like most service meshes, it’s based on injecting Envoy, the battle-tested sidecar proxy.
Kubernetes Service Mesh Comparison Tables
The six Kubernetes service mesh options presented here have a few things in common:
- Protocol support: They all work with HTTP, HTTP/2, gRPC, TCP, and WebSockets.
- They all have basic security in the form of mTLS between proxies by default.
- Service meshes, by design, provide some form of load balancing.
- These six, at least, also include a request retrying option among their traffic management features.
- Lastly, service discovery is a core feature of any service mesh.
But there are certainly differences worth highlighting when it comes to service mesh infrastructure, traffic management, observability, deployment, and other aspects.
Infrastructure
| Linkerd | Consul | Istio | Kuma | Traefik Mesh | AWS App Mesh | |
|---|---|---|---|---|---|---|
| Platforms | Kubernetes | Kubernetes, VM (Universal) | Kubernetes; VM (Universal) is in beta as of 1.9 | Kubernetes, VM (Universal) | Kubernetes | AWS EKS, ECS, FARGATE, EC2 |
| High Availability for Control Plane | Yes (creates exactly three control planes) | Yes (with extra servers and agents) | Yes (through Horizontal Pod Autoscaler [HPA] on Kubernetes) | Yes (horizontal scaling) | Yes (horizontal scaling) | Yes (by virtue of supporting AWS tech being HA) |
| Sidecar Proxy | Yes, linkerd-proxy | Yes, Envoy (can use others) | Yes, Envoy | Yes, Envoy | No | Yes, Envoy |
| Per-node Agent | No | Yes | No | No | Yes | No |
| Ingress Controller | Any | Envoy and Ambassador | Istio Ingress or Istio Gateway | Any | Any | AWS Ingress Gateway |
Traffic Management
| Linkerd | Consul | Istio | Kuma | Traefik Mesh | AWS App Mesh | |
|---|---|---|---|---|---|---|
| Blue-green Deployment | Yes | Yes (using traffic splitting) | Yes | Yes | Yes (using traffic splitting) | Yes |
| Circuit Breaking | No | Yes (through Envoy) | Yes | Yes | Yes | Yes |
| Fault Injection | Yes | No | Yes | Yes | No | No |
| Rate Limiting | No | Yes (through Envoy, with the help of official Consul docs) | Yes | Not yet, except by configuring Envoy directly | Yes | No |
Observability
| Linkerd | Consul | Istio | Kuma | Traefik Mesh | AWS App Mesh | |
|---|---|---|---|---|---|---|
| Monitoring with Prometheus | Yes | No | Yes | Yes | Yes | No |
| Integrated Grafana | Yes | No | Yes | Yes | Yes | No |
| Distributed Tracing | Yes (OpenTelemetry*) | Yes | Yes (OpenTelemetry*) | Yes | Yes (OpenTelemetry*) | Yes (AWS X-Ray or any open-source alternative) |
* OpenCensus and OpenTracing merged into OpenTelemetry in 2019, but you might find Linkerd articles referring to OpenCensus, as well as Istio and Traefik Mesh articles referring to OpenTracing.
Deployment
| Linkerd | Consul | Istio | Kuma | Traefik Mesh | AWS App Mesh | |
|---|---|---|---|---|---|---|
| Multicluster | Yes (recently) | Yes (federated) | Yes | Yes (multizone) | No | Yes |
| Mesh expansion | No | Yes | Yes | Yes | No | Yes (for AWS services) |
| GUI | Yes (out of the box) | Yes (Consul UI) | No native GUI but can use Kiali | Yes (native Kuma GUI) | No | Yes (through Amazon CloudWatch) |
| Deployment | via CLI | via Helm chart | via CLI, via Helm chart, or via operator container | via CLI, via Helm chart | via Helm chart | via CLI |
| Management Complexity | Low | Medium | High | Medium | Low | Medium |
Other Service Mesh Considerations
| Linkerd | Consul | Istio | Kuma | Traefik Mesh | AWS App Mesh | |
|---|---|---|---|---|---|---|
| Open Source | Yes | Yes | Yes | Yes | Yes | No |
| Exposed API | Yes, but not documented | Yes, and fully documented | Yes, entirely through CRDs | Yes, and fully documented | Yes, but intended for debugging (GET-only); also, SMI via CRDs | Yes, and fully documented |
| SMI Specification Support | Yes | Yes (partial) | Yes | No | Yes | No |
| Special Notes | Needs PostgreSQL to run outside of Kubernetes | Needs CoreDNS installed on its cluster | Fully managed by AWS |
Should We Use a Kubernetes Service Mesh?
Now that we have seen what service meshes are, how they work, and the multitude of differences between them, we can ask: Do we need a service mesh?
That’s the big question for SREs and cloud engineers these past few years. Indeed, microservices bring operational challenges in network communication that a service mesh can solve. But service meshes, for the most part, bring their own challenges when it comes to installation and operation.
One problem we can see emerging in many projects is that with service meshes, there is a gap between the proof-of-concept stage and the production stage. That is, it’s unfortunately rare for companies to achieve staging environments that are identical to production in every aspect; with service meshes involving crucial infrastructure, scale- and edge-related effects can bring deployment surprises.
Service meshes are still under heavy development and improvement. This could actually be attractive for teams with high deployment velocities—those who have mastered “the art of staying state-of-the-art” and can closely follow the development cycle of cloud-native tools.
For others, though, the pace of service mesh evolution could be more of a pitfall. It would be easy enough to set up a service mesh but then forget about the need to maintain it. Security patches may go unapplied or, even if remembered, may carry with them unplanned issues in the form of deprecated features or a modified set of dependencies.
There’s also a notable cost in terms of manpower to set up a service mesh in production. It would be a sensible goal for any team to evaluate this and understand if the benefits from a service mesh would outweigh the initial setup time. Service meshes are hard, no matter what the “easy” demo installations show.
In short, service meshes can solve some of the problems typical to projects deployed at scale but may introduce others, so be prepared to invest time and energy. In a hypothetical infrastructure involving 25 microservices and load of five queries per second, I would recommend having at least one person (preferably two) dedicated for at least a month to preparing a proof of concept and validating key aspects before thinking about running it in production. Once it’s set up, anticipate the need for frequent upgrades—they will impact a core component of your infrastructure, namely network communications.
Kubernetes Service Meshes: A (Complex) Evolution in Scalable App Architecture
We’ve seen what service meshes are: a suite of tooling to answer new challenges introduced by microservices architecture. Through traffic management, observability, service discovery, and enhanced security, service meshes can reveal deep insights into app infrastructure.
There are multiple actors on the market, sometimes promoted by GAFAM et al., that have in some cases open-sourced or promoted their own internal tooling. Despite two different implementation types, service meshes will always have a control plane—the brain of the system—and a data plane, made of proxies that will intercept the requests of your application.
Reviewing the three biggest service meshes (Linkerd, Consul Connect, and Istio) we have seen the different strategies they’ve chosen to implement and the advantages they bring. Linkerd, being the oldest service mesh on the market, benefits from its creators’ experience at Twitter. HashiCorp, for its part, offers the enterprise-ready Consul Connect, backed by a high level of expertise and support. Istio, which initially garnered ample attention online, has evolved into a mature project, delivering a feature-complete platform in the end.
But these actors are far from being the only ones, and some less-talked-about service meshes have emerged: Kuma, Traefik Mesh, and AWS App Mesh, among others. Kuma, from Kong, was created with the idea of making the service mesh idea “simple” and pluggable into any system, not just Kubernetes. Traefik Mesh benefited from experience with the preexisting Traefik Proxy and made the rare decision to eschew sidecar proxies. Last but not least, AWS decided to develop its own version of the service mesh, but one that relies on the dependable Envoy sidecar proxy.
In practice, service meshes are still hard to implement. Although service mesh benefits are compelling, their impact, critically, cuts both ways: Failure of a service mesh could render your microservices unable to communicate with each other, possibly bringing down your entire stack. A notorious example of this: Incompatibility between a Linkerd version and a Kubernetes version created a complete production outage at Monzo, an online bank.
Nonetheless, the whole industry is structuring itself around Kubernetes and initiatives like the Microsoft-spearheaded SMI, a standard interface for service meshes on Kubernetes. Among numerous other projects, the Cloud Native Computing Foundation (CNCF) has the Envoy-based Open Service Mesh (OSM) initiative, which was also originally introduced by Microsoft. The service mesh ecosystem remains abuzz, and I predict a champion emerging in the coming years, the same way Kubernetes became the de facto container orchestration tool.
This article was originally published in toptal.com Blog. Follow total.com for more articles.
About the Author

Guillaume is a seasoned DevOps engineer who is constantly searching for ways to improve automation to help developers deliver faster. With an entrepreneurial mindset, he is always ready to take on new challenges. His taste for fast-paced environments led him to Hong Kong where he set up the infrastructure of two startups and one hedge fund’s web application.
Disclaimer:
The views expressed and the content shared in all published articles on this website are solely those of the respective authors, and they do not necessarily reflect the views of the author’s employer or the techbeatly platform. We strive to ensure the accuracy and validity of the content published on our website. However, we cannot guarantee the absolute correctness or completeness of the information provided. It is the responsibility of the readers and users of this website to verify the accuracy and appropriateness of any information or opinions expressed within the articles. If you come across any content that you believe to be incorrect or invalid, please contact us immediately so that we can address the issue promptly.
Tags:
Latest posts





Comments
Leave a Reply